

股票配资是一种杠杆交易方式唐山股票配资,投资者通过借用资金放大投资规模,以期获得更高的收益。然而,配资交易也存在一定的风险,因此投资者在进行配资之前,需要进行充....

股票配资批发姜堰股票配资,是近年来兴起的一种新型投资方式,它以低门槛、高收益的特点吸引了众多投资者的目光。 * **放大资金杠杆:**投资者可以利用配资公司提供....

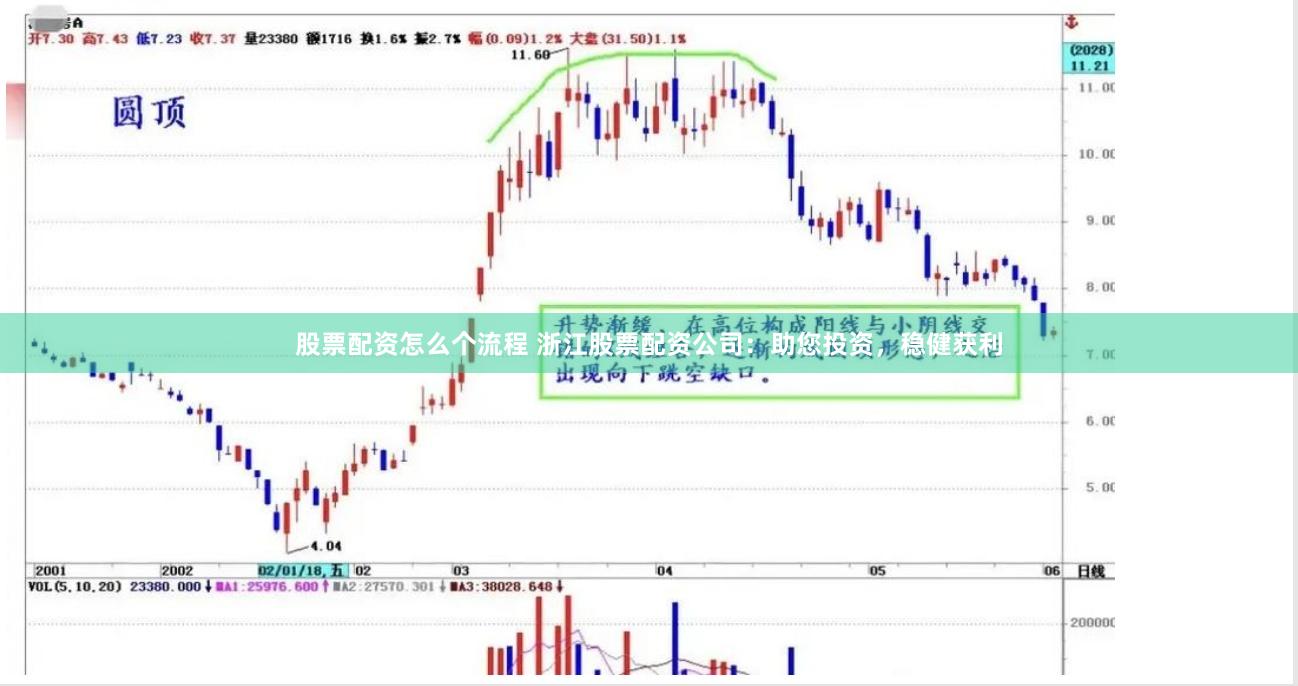
在浙江,股票配资已成为一种备受投资者青睐的投资方式。浙江股票配资公司通过提供杠杆资金,帮助投资者放大收益,实现稳健获利。 * **爆仓风险:**当股价大幅下跌时....
股票配资,是指投资者利用券商提供的资金杠杆,放大自己的投资资金,从而提高投资收益率的一种方式。对于资金有限的投资者来说白银股票配资,股票配资无疑是一个不错的选择....

期货配资是一种杠杆投资方式股票交易哪个证券公司好,可以放大投资收益,但同时也会增加风险。选择一个靠谱的期货配资平台至关重要,它能保障资金安全和交易稳定。 * *....

在股票市场中股票配资网门户,资金是关键。如果您没有足够的资金,您可能无法充分利用市场机会。这就是股票配资平台发挥作用的地方。 该网站会提供一些基础的知识介绍,如....
![股票配资网门户 寻找股票配资平台?尽在[平台名称]](/uploads/allimg/251125/2510132F10T03.jpg)
配资炒股是一种杠杆化的投资方式,它可以放大投资者的收益,但也同时增加了风险。对于有经验的投资者来说,配资炒股可以成为一种有效的投资工具。 - 通过借款来进行投资....
在股票市场中,配资是一种常见的融资方式什么是股票配资,可以放大投资者的资金规模,提高收益率。然而,选择正规的股票配资软件什么是股票配资至关重要,以确保资金安全和....

在瞬息万变的金融市场中,手机股票配资已成为投资者撬动资本、放大收益的利器。通过手机端便捷的操作,投资者可以轻松获得资金杠杆最新股票配资平台点评 ,扩大投资规模,....

股票配资是一种杠杆投资方式,允许投资者借用资金进行股票交易。它可以放大收益,但同时也增加了风险。 1. 贝格配资:贝格配资是国内知名的股票配资公司,提供专业的配....

内盘期货配资是一种金融杠杆工具,允许交易者通过借入资金来放大其交易规模。通过使用配资,交易者可以以较小的本金撬动更大的资金,从而提升潜在收益。 * **放大收益....
在银川证券公司就是炒股吗,股票配资正成为解锁财富新密码,为投资梦想注入强劲动力。股票配资是一种杠杆交易方式,投资者可以利用配资公司提供的资金放大投资规模,从而获....
在当今快节奏的金融市场中,股票配资已成为投资者提升收益的利器。股票配资神器是一款革命性的工具,它可以帮助投资者轻松获得杠杆资金,从而放大投资收益。 * **资金....

在股票投资领域,配资已成为一种常见的融资方式。为了帮助投资者选择正规可靠的配资平台,权威机构发布了正规股票配资排名榜单。 选择一家信誉良好的配资公司至关重要。考....

在当今快节奏的金融市场中,股票配资已成为投资者提升收益的有效工具。长沙股票配资平台为投资者提供资金杠杆,让他们能够放大投资规模,从而获得更高的潜在回报。 股票配....

股票配资是一种杠杆投资工具配资炒股开户官网,它允许投资者以较低的成本获得更高的投资收益。低息股票配资更是为投资者提供了绝佳的增值机会。 * **放大投资本金:*....
**第一步:选择正规配资平台**股票配资渠道 通过期货配资吧,您可以获得高达10倍的配资杠杆,这意味着您的资金可以瞬间放大10倍。这将极大地提高您的交易收益,让....

在配资炒股领域,选择一家靠谱的平台至关重要。资深玩家推荐以下平台,供投资者参考: 1. 手续费:配资平台会按照一定的比例收取手续费,一般是按照配资金额的千分之几....

配资炒股炒股配资网选,是指投资者通过配资平台向第三方借入资金,以扩大自己的投资规模。配资炒股配资网作为专业的配资平台,为投资者提供安全、便捷的配资服务,助力资金....

在股票投资领域,配资平台扮演着至关重要的角色。配资查询网应运而生配资炒股是,为投资者提供了一个全面、便捷的配资平台查询平台。 * **低门槛:**低至10%的保....

在股票投资领域,配资是放大收益的有效手段。然而股票基金配资,选择合适的配资平台至关重要,它直接影响投资者的资金安全和收益率。 配资买股的潜在收益率较高。由于杠杆....

个人股票配资是一种融资方式,允许投资者使用杠杆来放大其投资规模。通过向配资公司借入资金,投资者可以购买更多股票股票配资怎么收费,从而增加潜在收益。 * **资金....

股票配资是一种杠杆投资方式,可以放大投资收益,但同时也伴随着更高的风险。在选择股票配资平台时可靠的股票配资平台,需要把握以下要点: * **放大投资规模:**配....

在当今瞬息万变的金融市场中,股票配资已成为投资者提升收益率的有效工具。太仓股票配资,凭借其专业团队和完善的风险控制体系,为投资者提供安全可靠的配资服务。 此外,....
炒股配资证券公司买卖股票,是指投资者通过向配资公司借入资金,放大杠杆进行股票交易的行为。配资选得好,不仅能提高收益,还能保障资金安全。 通过互联网金融股票配资,....

攀枝花期货配资作为一种金融杠杆工具哪里有股票配资,为投资者提供了放大资金规模、提升收益潜力的机会。通过与正规配资公司合作,投资者可以获得额外的资金,从而扩大交易....

在瞬息万变的资本市场中,长春炒股配资炒股配资利息应运而生,为投资者提供了撬动财富杠杆的利器。配资,即通过借用资金进行股票投资,放大投资收益。 * **放大收益:....

实盘配资炒股是一种杠杆炒股方式,投资者通过向配资公司借款,放大资金规模进行股票交易。这种方式具有低成本、高收益的优势,成为众多投资者青睐的投资利器。 * **雪....
股指期货配资是近年来兴起的一种投资方式,它可以放大投资者的资金,提高收益率。然而,选择一个靠谱的配资平台至关重要。以下是一些推荐的平台: * **杠杆效应:**....

配资,是指投资者通过向配资公司借入资金,扩大投资规模的一种方式。对于新手买股票,配资可以放大收益,但同时也增加了风险股票配资查询。 1. 选择合适的配资平台:根....

在瞬息万变的股市中2016配资炒股平台,股指期货配资神器应运而生,为投资者提供了一把利器,助其轻松掌控市场。 配资实盘炒股开户流程非常简单。投资者只需选择一家正....

股票配资武汉股票配资,是指投资者利用杠杆资金放大投资本金,以提高投资收益的一种方式。为了满足投资者的配资需求,市面上涌现出众多股票配资平台。 1. **选择配资....

在瞬息万变的金融市场中炒股配资官网,股票配资成为投资者提升收益率的有效工具。杭州雷曼期货作为一家专业期货公司,推出股票配资服务,为投资者提供更从容的投资体验。 ....

正规期货配资是一种金融杠杆工具,通过向投资者提供资金杠杆,帮助他们放大投资资金,从而提高投资收益率。 我们的平台提供实时股票、指数、期货等行情数据,涵盖国内外主....

炒股配资是一种杠杆操作,可以放大投资收益,但同时也伴随更高的风险。对于初入门的投资者,了解配资的必备条件和注意事项至关重要。 * **资金放大:**配资可将投资....

配资炒股是一种杠杆炒股方式,通过借用资金放大投资额,从而提高收益率。配资炒股开户简单便捷,只需满足以下条件即可: * **杠杆放大收益:**投资者可通过配资放大....
股票配资网站为用户者提供专业的股票配资服务,帮助用户高效利用资金提升配资收益。便捷、安全、透明的配资平台,实时行情,让您轻松实现财富增值。



上证指数
深证成指
创业板指

期货市场作为高杠杆投资工具,为投资者提供了放大收益的机遇。合肥期货配资平台应运而生,为投资者提供资金杠杆,助力其提升投资
福建股票配资线上股票配资公司,为投资者开启了一条通往财富新篇章的康庄大道。通过配资,投资者可以轻松撬动股市杠杆,放大收益
正规股票配资是一种杠杆化的投资方式,通过向专业配资公司借入资金,投资者可以放大自己的投资本金,从而获得更高的收益。然而,
对于想要投资港股的投资者来说股票配资平台排名,港股配资是一个不容错过的利器。它可以帮助投资者放大资金杠杆,提高投资收益率
**引言** * **专业风控:**平台采用先进的风控系统,实时监控市场动态,及时预警风险,保障您的资金安全。 配资,又
在期货市场中,配资可以放大投资者的收益,但同时也增加了风险。因此,选择一家正规的期货配资公司至关重要。本文将揭秘正规期货
股票配资是一种杠杆交易方式股票配资交易软件,通过向券商借钱放大资金规模,从而提高投资收益。然而,配资交易也伴随着较高的风
股票配资是一种杠杆投资方式,投资者可以借用资金放大投资规模。然而,配资也伴随着利息成本,不同平台的利率差异较大。 配资的




